最近为了给 Twitter Monitor 增加几个翻译源,我研究了几个自带翻译功能的浏览器(不出意外全是 Chromium 系的)
Chrome
首先是老大哥 Chrome,自带的翻译源是 Google 翻译,作为我日常使用的浏览器,我觉得这玩意还是很有用的,处理 Google 翻译的 api 唯一的难点就是那个神秘的 tk ,这个值用于校验传入的内容是否有误,出错了直接送400不解释。
这个 tk 值的原理大概就是根据待翻译文本的每一个字符的 charCode 做计算得出一个的数组,再拿这个数组去做一系列的运算,我还是直接放代码吧
const hl = function (a, b) {
let c = 0
for (; c < b.length - 2; c += 3) {
let d = b.charAt(c + 2)
d = "a" <= d ? (d.charCodeAt(0) - 87) : Number(d)
d = "+" == b.charAt(c + 1) ? (a >>> d) : (a << d)
a = "+" == b.charAt(c) ? (a + d & 4294967295) : (a ^ d)
}
return a
}
const getCharCodeList = function (text) {
let charCodeList = [], charCodeListIndex = 0
for (let index = 0; index < text.length; index++) {
let charCode = text.charCodeAt(index)
if (128 > charCode) {
charCodeList[charCodeListIndex++] = charCode
} else {
if (2048 > charCode) {
charCodeList[charCodeListIndex++] = charCode >> 6 | 192
} else {
if (55296 == (charCode & 64512) && index + 1 < text.length && 56320 == (text.charCodeAt(index + 1) & 64512)) {
charCode = 65536 + ((charCode & 1023) << 10) + (text.charCodeAt(++index) & 1023)
charCodeList[charCodeListIndex++] = charCode >> 18 | 240
charCodeList[charCodeListIndex++] = charCode >> 12 & 63 | 128
} else {
charCodeList[charCodeListIndex++] = charCode >> 12 | 224
}
charCodeList[charCodeListIndex++] = charCode >> 6 & 63 | 128
}
charCodeList[charCodeListIndex++] = charCode & 63 | 128
}
}
return charCodeList
}
//https://translate.google.com/translate_a/element.js?cb=gtElInit&hl=zh-CN&client=wt c._ctkk
const GoogleTranslateTk = (originalText = '', tkk = [464385, 3806605782]) => {
//from https://translate.googleapis.com/_/translate_http/_/js/k=translate_http.tr.zh_CN.D7QeyoDkDhY.O/d=1/exm=el_conf/ed=1/rs=AN8SPfq20C5s1IToiD2r2PKoyh-SRQysPA/m=el_main
let text
if (originalText instanceof Array) {
text = JSON.parse(JSON.stringify(originalText)).join('')
} else {
text = originalText
}
const charCodeList = getCharCodeList(text)
let a = tkk[0]
for (const charCode of charCodeList) {
a += charCode
a = hl(a, '+-a^+6')
}
a = hl(a, '+-3^+b+-f')
a ^= tkk[1] ? tkk[1] + 0 : 0
if (a < 0) {
a = (a & 2147483647) + 2147483648
}
a %= 1E6
return a.toString() + '.' + (a ^ tkk[0])
}
其中函数 GoogleTranslateTk() 的传入值 tkk 是动态的,每隔一段时间都会更新,不过历史上出现过的任何一个 tkk 计算出来的值都是合法的,所以可以当作是固定的值
至于dom处理还是很简单粗暴的(还是比较好的了),Google 会对链接和特殊文本进行处理,链接会改成类似 <a id=${index}>${content}</a> 的格式,其中这个 index 就表示那段文字中的第几个链接,别的我忘了,后续再补上
Google 翻译太常用了,已经有大量前人研究过这玩意了,剩下的细节方面大家可以看这篇文章
Microsoft Edge
作为 Chromium 系的搅局者,Windows 系统自带的 Edge 那自然是不得不提的存在,Edge 浏览器自带的翻译源是微软翻译,作为前推文翻译的内容提供商(目前是Google),它的翻译质量还算是可以保障的,不过这家其实很简单,只需要获取一个 jwt 就能用了,这个 token 的有效时长不算很长,大约 9.5 分钟
const jwt = await axios.get('https://edge.microsoft.com/translate/auth')
const content = await axios.post(`https://api.cognitive.microsofttranslator.com/translate?from=&to=${target}&api-version=3.0&includeSentenceLength=true`, JSON.stringify(textArray.map(text => ({Text: text}))), {
headers: {
'content-type': 'application/json',
authorization: `Bearer ${jwt}`
}
})
这家是用奇奇怪怪的 <b${type}>${content}<b${type}> 来分割 dom,其中不同的 tag 会分配给不同的 type,比如 <a> 分配到的是20,<strong>分配到的是10
更多的玩法请看参考里面的链接
Yandex Browser
前两家翻译源都支持自动判断语言,但 yandex 翻译需要事先判断语言类型再传出去,通过查看 browser://translate-internals/ 可以得知道 Yandex 浏览器使用 CLD3 检测语言,可以通过 lang_162.js 找到支持的语言
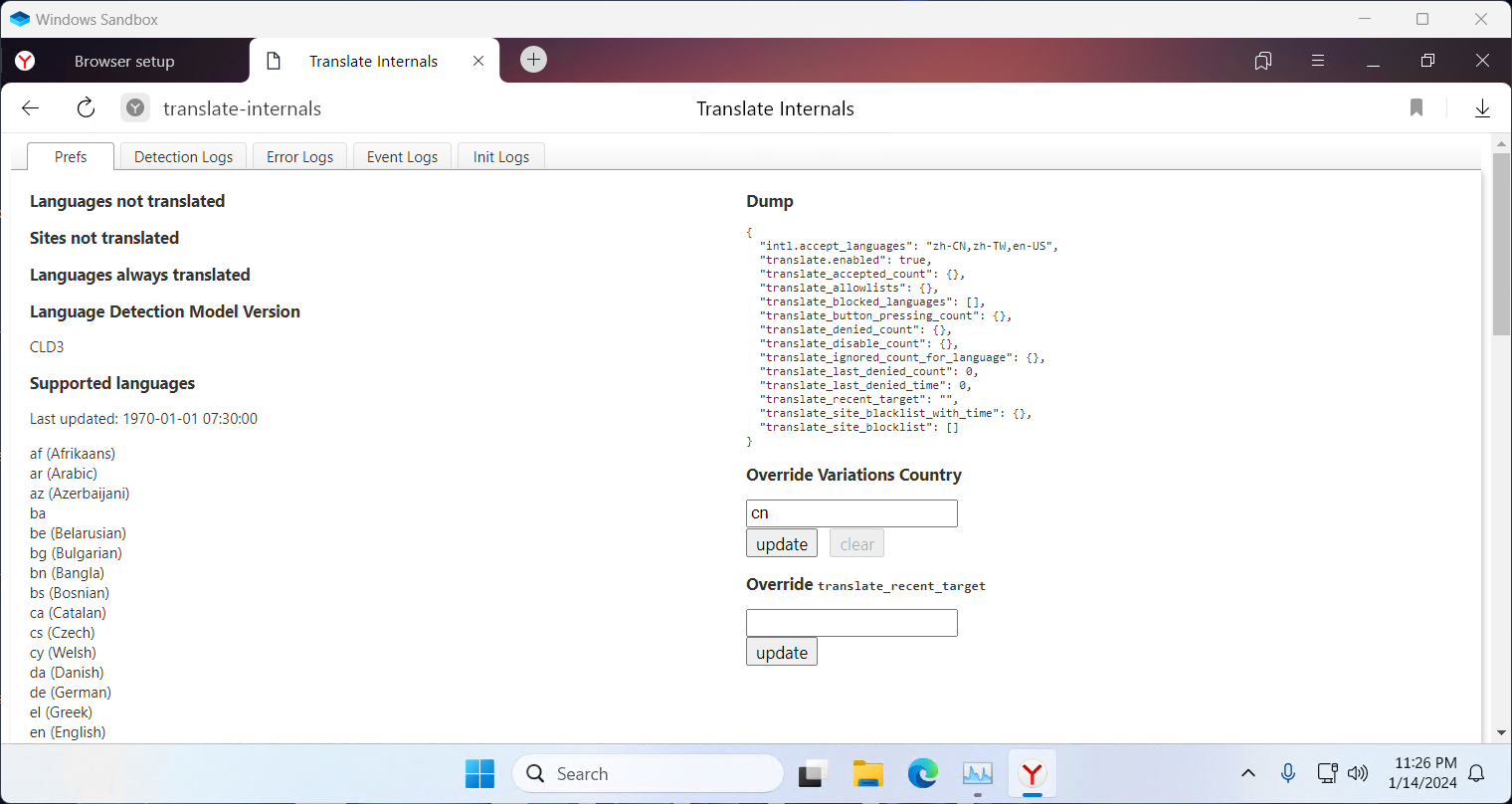
browser://translate-internals/
我选择使用 github:kwonoj/cld3-asm 判断,仓库里的示例代码已经写得很详细,我就不赘述了
至于 dom 处理跟 Chrome 差不多,直接参考 Chrome 的方案即可
lang = predictFromCLD3()//...
//from yandex browser
const generateSid = () => {
var t, e, n = Date.now().toString(16)
for (t = 0, e = 16 - n.length; t < e; t++) {
n += Math.floor(16 * Math.random()).toString(16)
}
return n
}
const supportedLanguageList = ["af","sq","am","ar","hy","az","ba","eu","be","bn","bs","bg","my","ca","ceb","zh","cv","hr","cs","da","nl","sjn","emj","en","eo","et","fi","fr","gl","ka","de","el","gu","ht","he","mrj","hi","hu","is","id","ga","it","ja","jv","kn","kk","kazlat","km","ko","ky","lo","la","lv","lt","lb","mk","mg","ms","ml","mt","mi","mr","mhr","mn","ne","no","pap","fa","pl","pt","pt-BR","pa","ro","ru","gd","sr","si","sk","sl","es","su","sw","sv","tl","tg","ta","tt","te","th","tr","udm","uk","ur","uz","uzbcyr","vi","cy","xh","sah","yi","zu"]
let query = new URLSearchParams({
translateMode: 'context',
context_title: 'Twitter Monitor Translator',//自定义的标题,可以自己改
id: `${generateSid()}-0-0`,
srv: 'yabrowser',
lang: `${lang}-${target}`,
format: 'html',
options: 2
})
const content = await axios.get('https://browser.translate.yandex.net/api/v1/tr.json/translate?' + query.toString() + '&text=' + (textArray.map(text => encodeURIComponent(text)).join('&text=')))
QQ 浏览器
作为国产浏览器的老大哥之一,QQ 浏览器的使用者还是挺多的,所以我拿它来作为最后一个研究的浏览器。
跟前面三家不一样,QQ 浏览器是用一个搜狗翻译的插件完成这个功能的,这个插件疑似调用了一些 QQ 浏览器的私有 api 或者是过时的 Chromium 的 api,反正我尝试在最新版本的 Chrome (Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36) 上加载解压后的拓展程序是用不了的,而 QQ 浏览器没直接在拓展程序页面提供调试插件的办法(难道他们自己都不用?),我懒得研究各种奇技淫巧就直接拆包了
反正没多复杂,很简单就解决了
25-01-05 补充:现在 content-type 从 application/x-www-form-urlencoded 变成 multipart/form-data 了
const body = new FormData()
body.append('S-Param', JSON.stringify({
from_lang: "auto",
to_lang: target,
trans_frag: textArray.map(text => ({text}))
}))
const content = await (await fetch('https://go.ie.sogou.com/qbpc/translate', {method: 'POST', body})).json()
我研究了一番发现它不会翻译 # ,所以理论上只需要用两个 # 包裹编号的格式就可以解决 dom 的问题了,大概就是 #${index}#
需要注意的是搜狗的 to_lang 是大小写敏感的,目标语言是中文时必须用 zh-CHS(看到测试没过的时候我是有点慌的)
百度翻译
研究之余我还有一个意外发现,百度翻译不再需要一顿复杂的拿 token 的流程了,鉴于百度 sign 的原理跟 Google 基本是一样的,只不过百度遇到长度大于30的字符串时会切割前中后各10个字符组成总长30的新字符串
const gtk = [320305, 131321201]//应该跟Google差不多,是永久有效的,最好还是实时获取啦
const baiduPrefix = (text) => {
let textArray = [...text]
if (textArray.length > 30) {
return textArray.slice(0, 10).join("") + textArray.slice(Math.floor(textArray.length / 2) - 5, Math.floor(textArray.length / 2) + 5).join("") + textArray.slice(-10).join("")
}
return text
}
const sign = GoogleTranslateTk(baiduPrefix(text), gtk)
别的还是自己去抓包啦,反正也不难
DeepL
2023-02-20 更新
其实这个的原理还是挺好分析的,以前还要逆向客户端,现在看看chrome插件源码就好了,细节方面我不敢说,免得这篇文章被 DeepL 干掉。不过这些细节在代码层面都是直接拍脸上的,所以不难,但不要想当然,所见的未必是原本的意思
碎碎念
- 腾讯系的翻译网站有三个!三个!我发现这个情况时还是很震撼的,这三个分别是 搜狗翻译、腾讯翻译君以及腾讯交互翻译
- 各家使用的语言代码都有自己的花样,不过一般都比较遵守
ISO 639的,百度比较特立独行搞了一堆乱七八糟的代码,不加预处理应该是没法跟其他源共用一套来源的 - 其实我还研究了 Safari,不过实在搞不来 iOS 的抓包外加后面查到有前人提到这个接口一过代理就会访问失败,最后只抓到一个 url: https://sequoia.apple.com
- 你说我为啥不研究研究360翻译?emmm自己看吧
我也不用!
不过他们好像自己套了一层代理,还挺有意思的
'https://elephant.browser.360.cn/?t=translate&m=google&anno=3&client=te_lib&format=html&v=1.0&key=AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw&logld=vTE_20200506_00&sl=en&tl=zh-CN&sp=nmt&tc=1&sr=1&tk=669631.848623&mode=1'
# body我懒得写了,反正就只是套了一层代理,别的格式是一样的
- 我写了两段正则表达式来判断简中还是繁中……虽然感觉很鸡肋,不过写都写了别浪费了
const isChs = (lang = 'zh') => /^zh(?:_|\-)(?:cn|sg|my|chs)|zh|chs|zho$/.test(lang.toLowerCase())
const isCht = (lang = 'zh_tw') => /^zh(?:_|\-)(?:tw|hk|mo|cht)|cht$/.test(lang.toLowerCase())